Node의 기본 fetch를 사용하여 크롤링을 시도할 경우 요청이 차단되는 경우가 있다. 대표적으로 네이버의 검색이나 리뷰에 대한 크롤링을 시도할 때 이를 확인할 수 있다.
아래는 크롤링 요청 예시 코드이다.
import fs from "fs";
fetch("<https://smartstore.naver.com/geonlab/products/10453317502>", {
headers: {
accept: "text/html",
"accept-language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"sec-ch-ua": '"Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"',
"user-agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
},
})
.then(res => {
console.log(res.headers);
return res.text()}).then(console.log)
PS D:\\programming\\bun-test> node .\\index.js
위 코드를 node를 사용하여 실행시켜보면 아래와 같은 결과 값을 받게 된다.
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<title>[에러] 에러페이지 - 시스템오류</title>
<style type="text/css">
body {
min-width: 1320px
}
body,
p,
h1,
h2,
h3,
h4,
h5,
h6,
ul,
ol,
li,
dl,
dt,
dd,
table,
th,
td,
......
이는 네이버 스마트스토어에서 크롤링을 방지하기 위해 Node에서 오는 요청을 거부하기 때문에 발생하는 문제이다. 네이버뿐만 아니라 Cloudflare를 사용하는 여러 사이트 등 일정 수준의 접속자가 있는 웹 서버에서 크롤링 방지를 위해 Node의 요청을 차단하는 경우를 흔히 확인할 수 있다.
물론 Puppeteer를 사용하면 실제 브라우저 환경에서 요청하는 것처럼 동작하므로 이를 우회할 수 있지만, 상당히 번거로운 일이다. 또 하나의 우회 방법으로 fetch의 헤더를 직접 수정하는 방법도 있지만, 이것도 쉬운 방법은 아니다.
이번 글에서는 bun을 활용하여 크롤링 방지를 손쉽게 우회하는 방법을 다뤄보도록 하겠다. 이 방법을 사용하면 Cloudflare를 비롯한 여러 사이트의 크롤링 방지 코드를 우회할 수 있다. 이 방법을 우연히 알게 된 뒤 관련 자료를 찾아봤지만 어디에서도 관련 정보를 찾을 수 없었으며, 아직 알려지지 않은 방법이기에 유용하게 활용할 수 있을 것이다. 다만, 이 방법이 널리 퍼지거나 이슈화된다면 언제든지 막힐 수 있다는 점을 고려하여 사용하는 것을 추천한다.
또한, 이 방법이 모든 상황에서 완벽하게 작동하는 것은 아니다. 웹 서버의 크롤링 방어 구현 방식에 따라 결과가 다를 수 있으니 상황에 맞게 활용해야 한다.
우회 방법은 간단하다. 같은 코드를 단순하게 bun으로 실행시키면 된다. 아래는 위에서 작성한 동일한 코드를 bun으로 실행시켰을 때의 결과값이다.
D:\\programming\\bun-test> bun .\\index.js
<html lang="ko">
<head>
<meta charset="utf-8">
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" >
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="[GEONWORKS] 지온웍스 - 자체 제작 커스텀 키보드, 키보드 스위치, 윤활제, 키캡, 툴 생산 및 판매">
<meta name="keywords" content="키캡,키캡놀이,데스크테리어,기계식키보드,클래식키캡,빈티지,키보드키,디자인소품,이집트,기타PC액세서리,FBB,FBB,FBB T52 키캡 베이스킷,GEONWORKS">
<meta property="og:title" content="FBB T52 키캡 베이스킷 : GEONWORKS">
<meta property="og:image" content="https://shop-phinf.pstatic.net/20240614_13/1718348783758qU42w_PNG/6830707662541087_1178483238.png?type=o1000">
<meta property="og:description" content="[GEONWORKS] 지온웍스 - 자체 제작 커스텀 키보드, 키보드 스위치, 윤활제, 키캡, 툴 생산 및 판매">
<meta property="og:type" content="article">
<meta name="twitter:title" content="FBB T52 키캡 베이스킷 : GEONWORKS">
<meta name="twitter:image" content="https://shop-phinf.pstatic.net/20240614_13/1718348783758qU42w_PNG/6830707662541087_1178483238.png?type=o1000">
<meta name="twitter:description" content="[GEONWORKS] 지온웍스 - 자체 제작 커스텀 키보드, 키보드 스위치, 윤활제, 키캡, 툴 생산 및 판매">
<meta name="twitter:card" content="summary_large_image">
위에서 보이는 것처럼 크롤링에 의해 차단된 결과값이 아닌, 제대로 된 결과값을 받은 것을 확인할 수 있다.
그렇다면 왜 이것이 가능한 것일까? 일단 Bun 내부에 탑재된 fetch의 동작이 Node의 fetch와는 다르게 작동한다는 것은 확실하다고 말할 수 있다.
내부에서 헤더를 조금 다르게 설정해주는 것으로 추측되지만, 이를 확인하는 것은 쉽지 않아보인다.
그래도 궁금하니 일단 좀 더 조사해보기로 결정했다.
HTTP 요청을 자세히 확인해야 하므로 이를 캡처하기 위해 Fiddler를 설치해준다.
https://www.telerik.com/download/fiddler
Download Fiddler Web Debugging Tool for Free by Telerik
Download and install Fiddler Classic web debugging tool. Watch a quick tutorial to get started.
www.telerik.com
이후 Fiddler를 실행한 뒤 Node를 통해 위 코드를 다시 실행해보았다.
Node로 실행했을 때는 Fiddler에서 해당 요청이 캡처되지 않았기에 원인을 검색해 보니 Fiddler를 통해 요청을 캡처하기 위해서는 프록시를 통해 요청을 보내야 하며, Node에서는 기본적으로 프록시가 설정되어 있지 않기 때문에 요청이 캡처되지 않는다는 것이 원인이였다. 일단 이 정보는 뒤로한 채로 Bun을 사용하여 다시 한 번 요청을 보내보았다.

Bun의 HTTP 요청은 Fiddler에서 캡처되는 것을 확인할 수 있었다. Bun을 사용한 요청은 프록시가 자동으로 설정되는 것인가 하는 생각이 들지만 내부에서 어떻게 동작하는지는 아직 잘 모르겠으니, 이것저것 더 테스트를 진행해보자.
node에서의 요청도 확인하기 위해 먼저 fetch에 프록시를 설정해주어야 한다. 프록시 설정을 위해 기본 fetch가 아닌 node-fetch를 사용하도록 코드를 수정하고, 프록시를 직접 설정하여 Fiddler에서 해당 요청을 캡처해보자.
import fs from "fs";
import fetch from "node-fetch";
import { HttpsProxyAgent } from 'https-proxy-agent';
fetch("<https://smartstore.naver.com/geonlab/products/10453317502>", {
agent:new HttpsProxyAgent(''),
headers: {
accept: "text/html",
"accept-language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"sec-ch-ua": '"Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"',
"user-agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
},
})
.then(res => res.text()).then((res)=>{
fs.writeFileSync("result.html", res);
})
코드를 위와 같이 수정한 뒤 다시 요청을 해보았다.

이제 Fiddler에서 Node와 Bun의 요청이 모두 캡처되는 것을 확인할 수 있다.
위쪽은 Node의 요청이고 아래쪽은 Bun의 요청이며, Node 요청은 429 상태 코드와 함께 실패하는 것을 볼 수 있다.
429는 'Too Many Requests'로, 웹 서버 측에서 의도적으로 크롤러로 의심되는 요청을 차단했다는 의미로 추정된다.
이제 두 요청의 헤더 값을 복사하여 비교해보자.
먼저 아래는 Node fetch의 헤더 값이다.
GET <https://smartstore.naver.com/geonlab/products/10453317502> HTTP/1.1
accept: text/html
accept-encoding: gzip, deflate, br
accept-language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
sec-ch-ua: "Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36
Host: smartstore.naver.com
Connection: close
그리고 아래는 bun fetch의 헤더값이다.
GET <https://smartstore.naver.com/geonlab/products/10453317502> HTTP/1.1
accept: text/html
accept-language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
sec-ch-ua: "Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36
Connection: keep-alive
Host: smartstore.naver.com
Accept-Encoding: gzip, deflate, br
HTTP/1.1 200 OK
Server: nginx
Date: Fri, 20 Sep 2024 08:49:25 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Encoding
Cache-Control: no-cache, no-store, must-revalidate
requestid: 5a8d13b9-c4d4-4389-9ce1-4e71bb36f73d
Referrer-Policy: no-referrer-when-downgrade
X-UA-Compatible: IE=Edge,chrome=1
Content-Encoding: gzip
여기서 주의 깊게 봐야 할 부분은 Connection 헤더이다. Node에서의 Connection은 close로 되어 있으며, Bun에서의 Connection은 keep-alive로 설정되어 있다.
이는 어느 정도 다른 결과를 반환할 가능성이 있어 보이므로, Node의 fetch에서 헤더의 Connection 부분에 keep-alive를 명시하여 다시 요청해 보았다.

node에서의 요청이 성공한 것을 확인할 수 있었다. Bun의 fetch에서는 내부적으로 헤더의 Connection 부분에 명시적으로 keep-alive를 추가하여 요청하기 때문에 이러한 차이가 발생하는 것일까 하는 생각이 들기 시작했다. 아직 정확한 원인을 찾지 못했으므로 이 정보를 기억해 두고 의심가는 다른 부분들을 좀 더 조사해 보았다.
원인을 찾던 중 또 다른 문제를 발견했다. node-fetch를 사용하지 않고 Node의 기본 fetch를 사용할 때는 Connection의 값을 keep-alive로 설정해도 요청이 실패한다는 점이다. 이 쯤 되니 경우의 수가 너무 많이 나와 어떤 경우에 요청이 성공하는지 실패하는지가 헷갈리기 시작하였다. 지금까지의 테스트 결과를 한 눈에 파악하기 위해 표로 정리해 보았다.
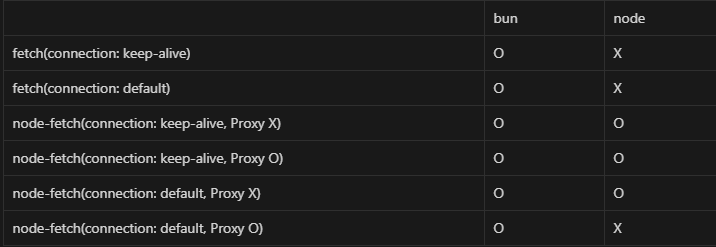
일단 Bun에서는 모두 잘 동작하는 것을 확인할 수 있었으며, Node의 기본 fetch는 모두 실패하는 것을 확인할 수 있었다.
좀 특이하게도 node-fetch의 경우에는 특정 설정을 추가해주면 요청이 성공하는 모습을 볼 수 있었다.
상식적으로 생각해보면, fetch에서 Connection 헤더의 기본값은 keep-alive일 것 같아서 공식 문서를 확인해보았다.
MDN 문서를 확인해보니, 예상대로 HTTP 1.1 버전의 Connection 헤더 기본값은 keep-alive로 명시되어 있는 것을 확인할 수 있었다..
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Connection
Directives
closeIndicates that either the client or the server would like to close the connection. This is the default on HTTP/1.0 requests.[any comma-separated list of HTTP headers Usually keep-alive only]Indicates that the client would like to keep the connection open. Keeping a connection open is the default on HTTP/1.1 requests. The list of headers are the name of the header to be removed by the first non-transparent proxy or cache in-between: these headers define the connection between the emitter and the first entity, not the destination node.
그런데 왜 프록시를 적용했을 때 Connection 값이 기본적으로 close로 적용되는 것일까? node-fetch 코드를 디버깅하여 따라가 보았다.
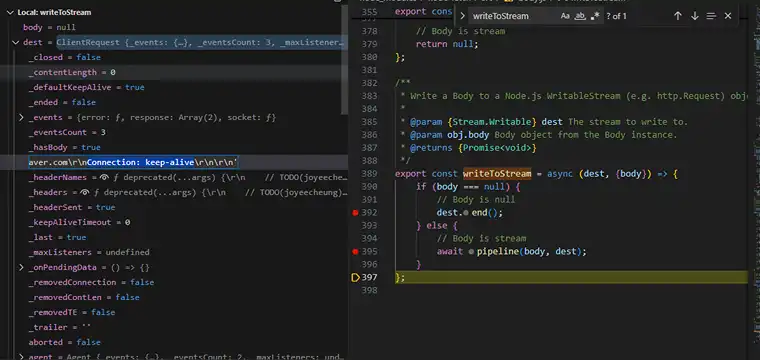
먼저 프록시를 적용하지 않았을 경우 node-fetch 내부의 dest.end() 함수가 실행되면서 _header 값의 Connection에 정상적으로 기본값인 keep-alive가 적용되는 모습을 확인할 수 있다.
하지만 프록시를 적용하면 아래와 같이 Connection에 close가 들어가서 close로 요청이 가는 것을 확인할 수 있었다.
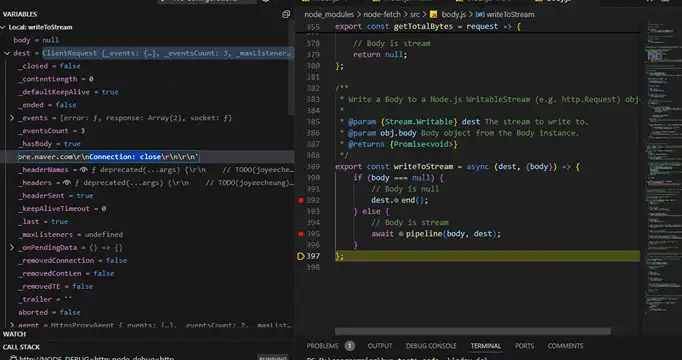
이 문제가 node-fetch의 버그인지 의도된 것인지는 내부 구현부를 더 살펴봐야 알겠지만, 일단 주제에서 벗어나는 것 같으니 원점으로 돌아가 보겠다.
지금까지 알아낸 내용은 Connection의 값이 close로 들어가면 크롤러로 판단하여 웹 서버에서 요청을 거부한다는 것과, Bun에서는 이와 상관없이 잘 동작한다는 것이다. 실제로 Connection의 값을 close로 강제로 넣어주어도 Bun에서는 문제없이 동작하는 것을 확인할 수 있었다.
또한 Node와 node-fetch를 함께 사용하면 내장된 fetch와는 다르게 요청이 성공하는 것도 확인할 수 있었으며, node-fetch에서 요청이 실패하는 것은 프록시 때문이라기보다 프록시가 Connection 값을 close로 바꿔서 발생하는 문제임을 찾아낼 수 있었다.
- 추가적으로, 위 테스트는 윈도우에서 진행했는데 맥에서 진행해보니 node-fetch의 요청도 무조건 실패하는 것을 확인할 수 있었다. (흠...)
단기간에 원인을 찾아내기는 어려워 보이며, 현재 할 일이 많으니 일들이 마무리된 뒤 원인을 찾아서 글을 마저 작성하도록 하겠다.
2편 보러가기
(언제 막힐지 모르는)Bun을 사용한 크롤링 방지 우회 방법과 원리(2)
1편 보러가기https://jjongsk.tistory.com/manage/newpost/85?type=post&returnURL=https%3A%2F%2Fjjongsk.tistory.com%2Fmanage%2Fposts 티스토리좀 아는 블로거들의 유용한 이야기, 티스토리. 블로그, 포트폴리오, 웹사이트까지
jjongsk.tistory.com
'etc' 카테고리의 다른 글
| 당근(당근마켓) 최종 면접 회고 (1) | 2025.01.14 |
|---|---|
| (언제 막힐지 모르는)Bun을 사용한 크롤링 방지 우회 방법과 원리(2) (0) | 2024.11.28 |
| 기가막힌 디자인/개발 툴 소개(v0.dev) (3) | 2024.10.06 |
| 기술 블로그와 시니어 개발자(나의 생각) (7) | 2024.09.04 |
| CRLF와 LF (0) | 2024.08.08 |